【求助贴】在《基于公司制度RAG》中的demo.py 运行时候报错。 #184
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
3 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#184
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
报错位置: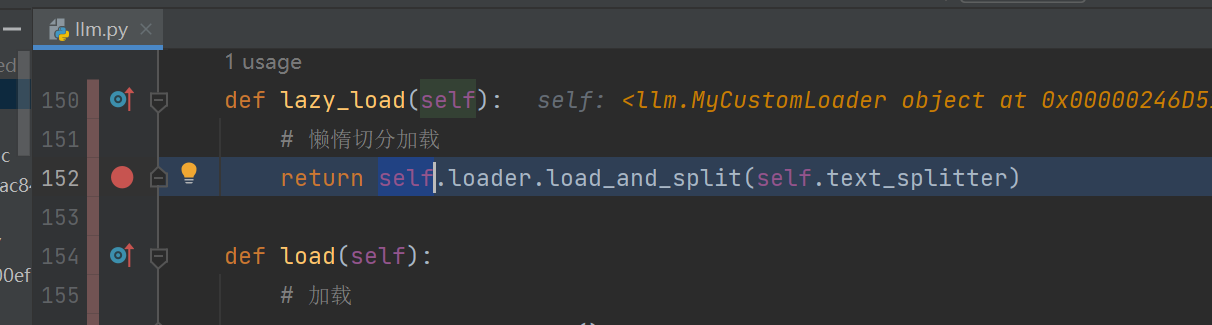
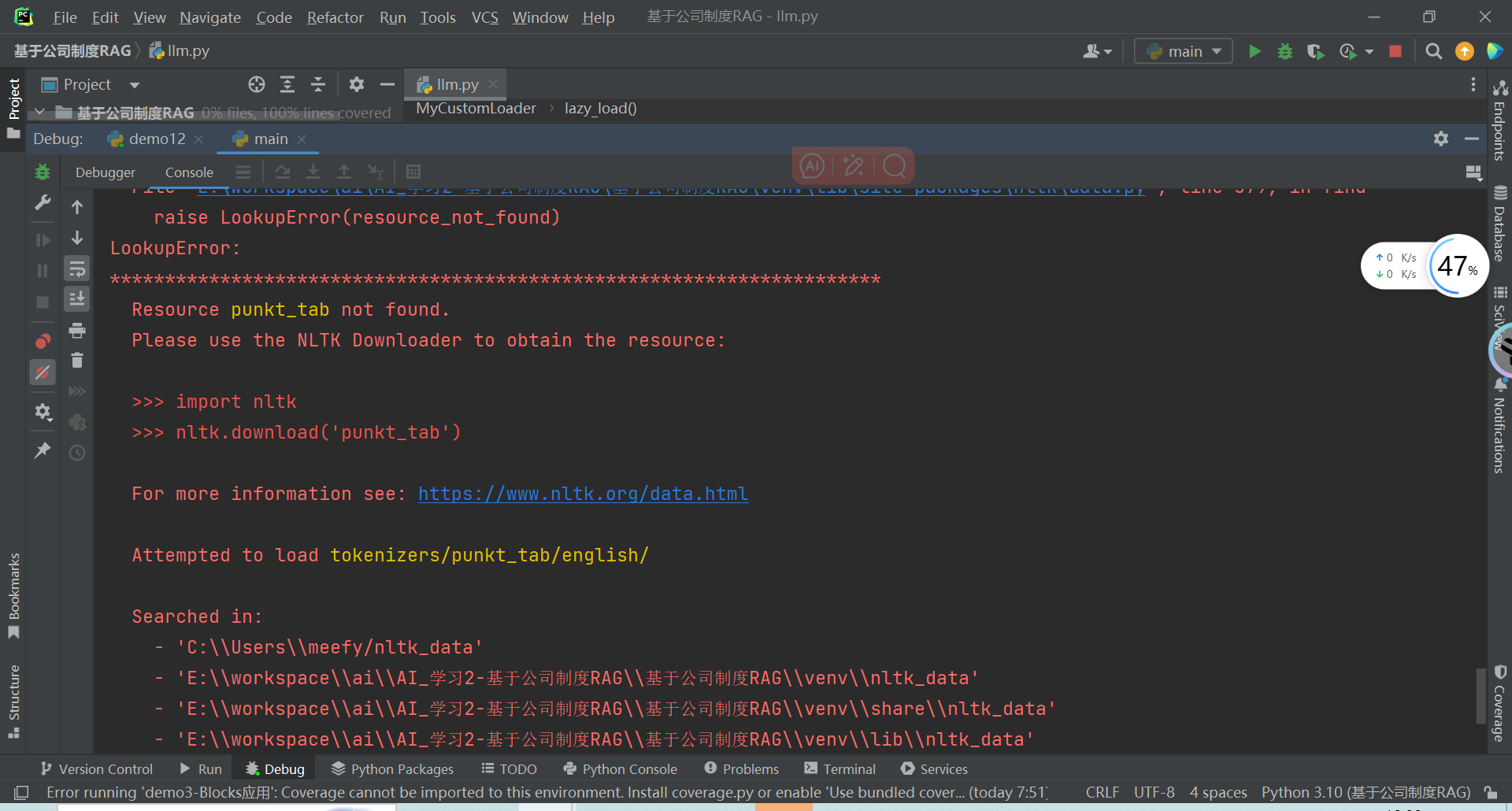
报错:
E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\Scripts\python.exe E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\main.py __embeddings: client=SentenceTransformer( (0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel (1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True}) (2): Normalize() ) model_name='./BAAI/bge-large-zh-v1.5' cache_folder=None model_kwargs={'device': 'cpu'} encode_kwargs={} query_instruction='为这个句子生成表示以用于检索相关文章:' embed_instruction='' show_progress=False __chat_history: os.listdir(KNOWLEDGE_DIR): ['中国人工智能系列白皮书(1).pdf', '中国人工智能系列白皮书.pdf', '人事管理流程(1).docx', '人事管理流程.docx'] file_path: ./chroma/knowledge/中国人工智能系列白皮书(1).pdf collection_name: 33c66cec79a243d518338e5fd391755c self.__retrievers: {} loader_class: <class 'langchain_community.document_loaders.pdf.PyPDFLoader'> params: {} self.loader: <langchain_community.document_loaders.pdf.PyPDFLoader object at 0x000001E04DBDE5C0> loader: <llm.MyCustomLoader object at 0x000001E04DBDD000> E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\llm.py:83: LangChainDeprecationWarning: The classChromawas deprecated in LangChain 0.2.9 and will be removed in 1.0. An updated version of the class exists in the langchain-chroma package and should be used instead. To use it runpip install -U langchain-chromaand import asfrom langchain_chroma import Chroma`.db = Chroma(collection_name=collection_name,
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DB6E320>
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DB6E320>
record_manager.create_schema: None
E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\gradio\analytics.py:106: UserWarning: IMPORTANT: You are using gradio version 4.44.1, however version 5.0.1 is available, please upgrade.
warnings.warn(
r: {'num_added': 0, 'num_updated': 0, 'num_skipped': 149, 'num_deleted': 0}
ensemble_retriever: retrievers=[VectorStoreRetriever(tags=['Chroma', 'HuggingFaceBgeEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x000001E04E4B8E20>, search_kwargs={'k': 3}), BM25Retriever(vectorizer=<rank_bm25.BM25Okapi object at 0x000001DF8B7729E0>)] weights=[0.5, 0.5]
collections: [None, '中国人工智能系列白皮书(1).pdf']
file_path: ./chroma/knowledge/中国人工智能系列白皮书.pdf
collection_name: 503dc7d31f89743234dc87e712078441
self.__retrievers: {'33c66cec79a243d518338e5fd391755c': EnsembleRetriever(retrievers=[VectorStoreRetriever(tags=['Chroma', 'HuggingFaceBgeEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x000001E04E4B8E20>, search_kwargs={'k': 3}), BM25Retriever(vectorizer=<rank_bm25.BM25Okapi object at 0x000001DF8B7729E0>)], weights=[0.5, 0.5])}
loader_class: <class 'langchain_community.document_loaders.pdf.PyPDFLoader'>
params: {}
self.loader: <langchain_community.document_loaders.pdf.PyPDFLoader object at 0x000001E04DB6E320>
loader: <llm.MyCustomLoader object at 0x000001E04DFD13F0>
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DBDD000>
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DBDD000>
record_manager.create_schema: None
r: {'num_added': 0, 'num_updated': 0, 'num_skipped': 149, 'num_deleted': 0}
ensemble_retriever: retrievers=[VectorStoreRetriever(tags=['Chroma', 'HuggingFaceBgeEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x000001E04DBDE5C0>, search_kwargs={'k': 3}), BM25Retriever(vectorizer=<rank_bm25.BM25Okapi object at 0x000001E04DFF6020>)] weights=[0.5, 0.5]
collections: [None, '中国人工智能系列白皮书(1).pdf', '中国人工智能系列白皮书.pdf']
file_path: ./chroma/knowledge/人事管理流程(1).docx
collection_name: fcdd3626ccf286e5b30ffcf77274f518
self.__retrievers: {'33c66cec79a243d518338e5fd391755c': EnsembleRetriever(retrievers=[VectorStoreRetriever(tags=['Chroma', 'HuggingFaceBgeEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x000001E04E4B8E20>, search_kwargs={'k': 3}), BM25Retriever(vectorizer=<rank_bm25.BM25Okapi object at 0x000001DF8B7729E0>)], weights=[0.5, 0.5]), '503dc7d31f89743234dc87e712078441': EnsembleRetriever(retrievers=[VectorStoreRetriever(tags=['Chroma', 'HuggingFaceBgeEmbeddings'], vectorstore=<langchain_community.vectorstores.chroma.Chroma object at 0x000001E04DBDE5C0>, search_kwargs={'k': 3}), BM25Retriever(vectorizer=<rank_bm25.BM25Okapi object at 0x000001E04DFF6020>)], weights=[0.5, 0.5])}
loader_class: <class 'langchain_community.document_loaders.word_document.UnstructuredWordDocumentLoader'>
params: {}
self.loader: <langchain_community.document_loaders.word_document.UnstructuredWordDocumentLoader object at 0x000001E04FB165C0>
loader: <llm.MyCustomLoader object at 0x000001E04FB14C10>
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DFD13F0>
record_manager: <langchain.indexes._sql_record_manager.SQLRecordManager object at 0x000001E04DFD13F0>
record_manager.create_schema: None
Traceback (most recent call last):
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\main.py", line 101, in
collection = gr.Dropdown(choices=llm.load_knowledge(), label="知识库")
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\llm.py", line 212, in load_knowledge
self.__retrievers[collection_name] = create_indexes(collection_name, loader, self.__embeddings)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\llm.py", line 95, in create_indexes
documents = loader.load()
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\llm.py", line 156, in load
return self.lazy_load()
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\llm.py", line 152, in lazy_load
return self.loader.load_and_split(self.text_splitter)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\langchain_core\document_loaders\base.py", line 64, in load_and_split
docs = self.load()
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\langchain_core\document_loaders\base.py", line 30, in load
return list(self.lazy_load())
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\langchain_community\document_loaders\unstructured.py", line 107, in lazy_load
elements = self._get_elements()
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\langchain_community\document_loaders\word_document.py", line 126, in _get_elements
return partition_docx(filename=self.file_path, **self.unstructured_kwargs)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\documents\elements.py", line 593, in wrapper
elements = func(*args, **kwargs)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\file_utils\filetype.py", line 626, in wrapper
elements = func(*args, **kwargs)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\file_utils\filetype.py", line 582, in wrapper
elements = func(*args, **kwargs)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\chunking\dispatch.py", line 74, in wrapper
elements = func(*args, **kwargs)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\docx.py", line 177, in partition_docx
return list(elements)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\lang.py", line 399, in apply_lang_metadata
elements = list(elements)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\docx.py", line 410, in _iter_document_elements
yield from self._iter_paragraph_elements(block_item)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\docx.py", line 634, in _iter_paragraph_elements
yield from self._classify_paragraph_to_element(item)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\docx.py", line 471, in _classify_paragraph_to_element
TextSubCls = self._parse_paragraph_text_for_element_type(paragraph)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\docx.py", line 938, in _parse_paragraph_text_for_element_type
if is_possible_narrative_text(text):
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\text_type.py", line 80, in is_possible_narrative_text
if exceeds_cap_ratio(text, threshold=cap_threshold):
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\text_type.py", line 276, in exceeds_cap_ratio
if sentence_count(text, 3) > 1:
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\partition\text_type.py", line 225, in sentence_count
sentences = sent_tokenize(text)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\unstructured\nlp\tokenize.py", line 30, in sent_tokenize
return sent_tokenize(text)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\nltk\tokenize_init.py", line 119, in sent_tokenize
tokenizer = get_punkt_tokenizer(language)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\nltk\tokenize_init.py", line 105, in _get_punkt_tokenizer
return PunktTokenizer(language)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\nltk\tokenize\punkt.py", line 1744, in init
self.load_lang(lang)
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\nltk\tokenize\punkt.py", line 1749, in load_lang
lang_dir = find(f"tokenizers/punkt_tab/{lang}/")
File "E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\site-packages\nltk\data.py", line 579, in find
raise LookupError(resource_not_found)
LookupError:
Resource punkt_tab not found.
Please use the NLTK Downloader to obtain the resource:
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt_tab/english/
Searched in:
- 'C:\Users\meefy/nltk_data'
- 'E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\nltk_data'
- 'E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\share\nltk_data'
- 'E:\workspace\ai\AI_学习2-基于公司制度RAG\基于公司制度RAG\venv\lib\nltk_data'
- 'C:\Users\meefy\AppData\Roaming\nltk_data'
- 'C:\nltk_data'
- 'D:\nltk_data'
- 'E:\nltk_data'
INFO:backoff:Backing off send_request(...) for 0.1s (requests.exceptions.ReadTimeout: HTTPSConnectionPool(host='us.i.posthog.com', port=443): Read timed out. (read timeout=15))
Process finished with exit code 1
`
#11248284577cs
下载包
我是不是把你这个问题解决了,如果没有的话,请联系 => 先知
解决了