【求助帖】2024-10-20 基于LLaMA-Factory的模型微调训练过程中报错,查看控制台日志发现有一处有问题 #273
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
6 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#273
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
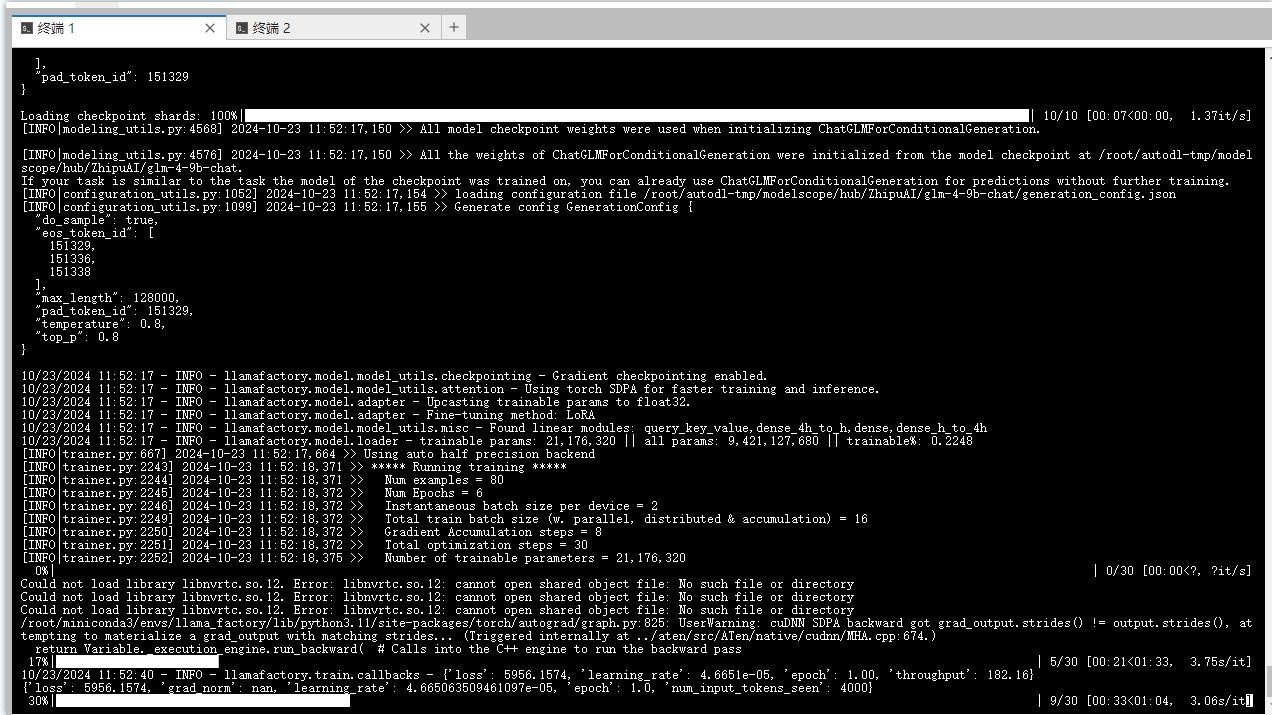
发现有一处报错:Could not load library libnvrtc.so.12. Error: libnvrtc.so.12: cannot open shared object file: No such file or directory,如下图:
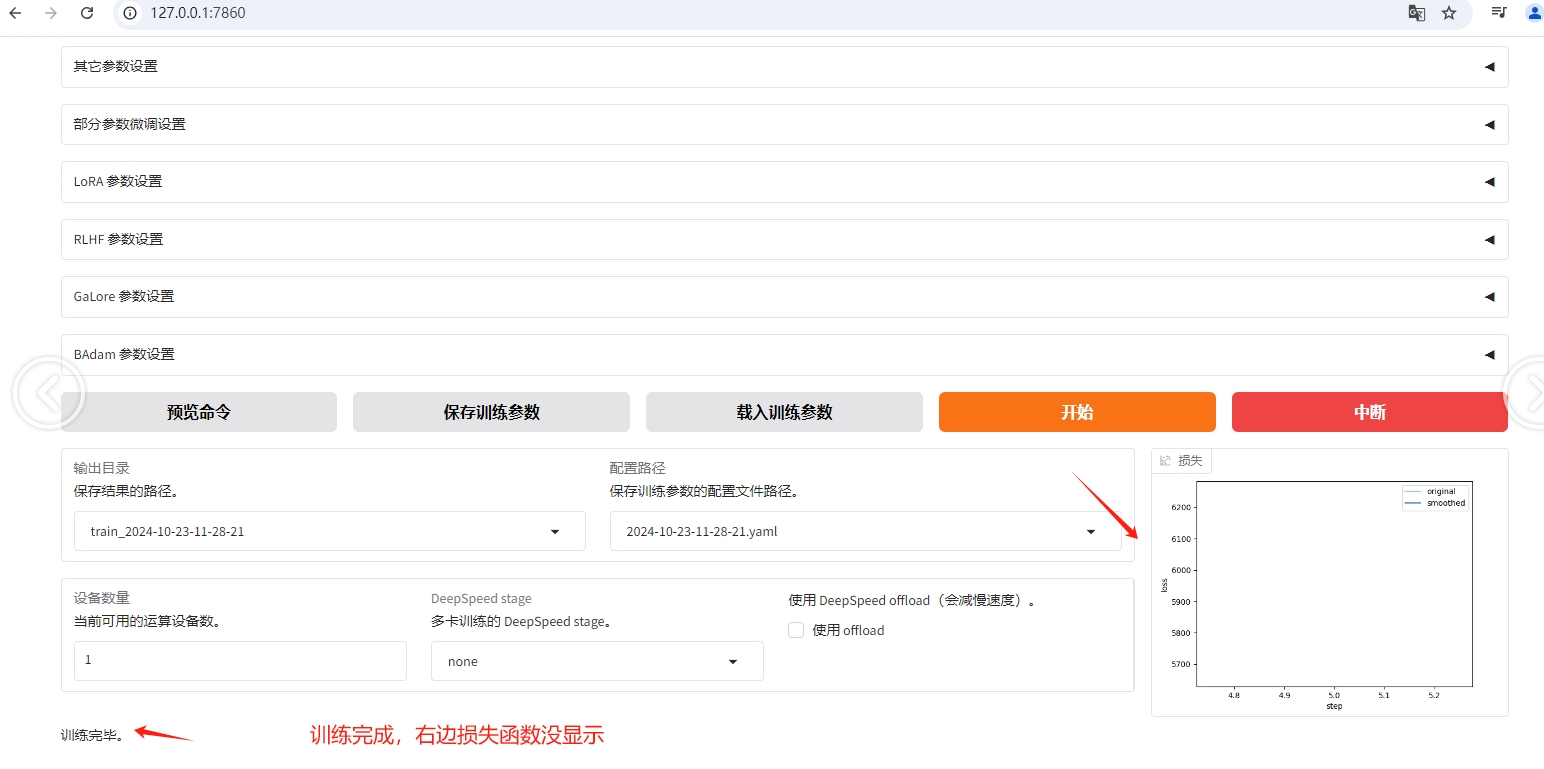
通过界面http://127.0.0.1:7860/ 看是:训练完毕,但是损失函数曲线图没出来。加载此检查点,提问后回答就不正常了。
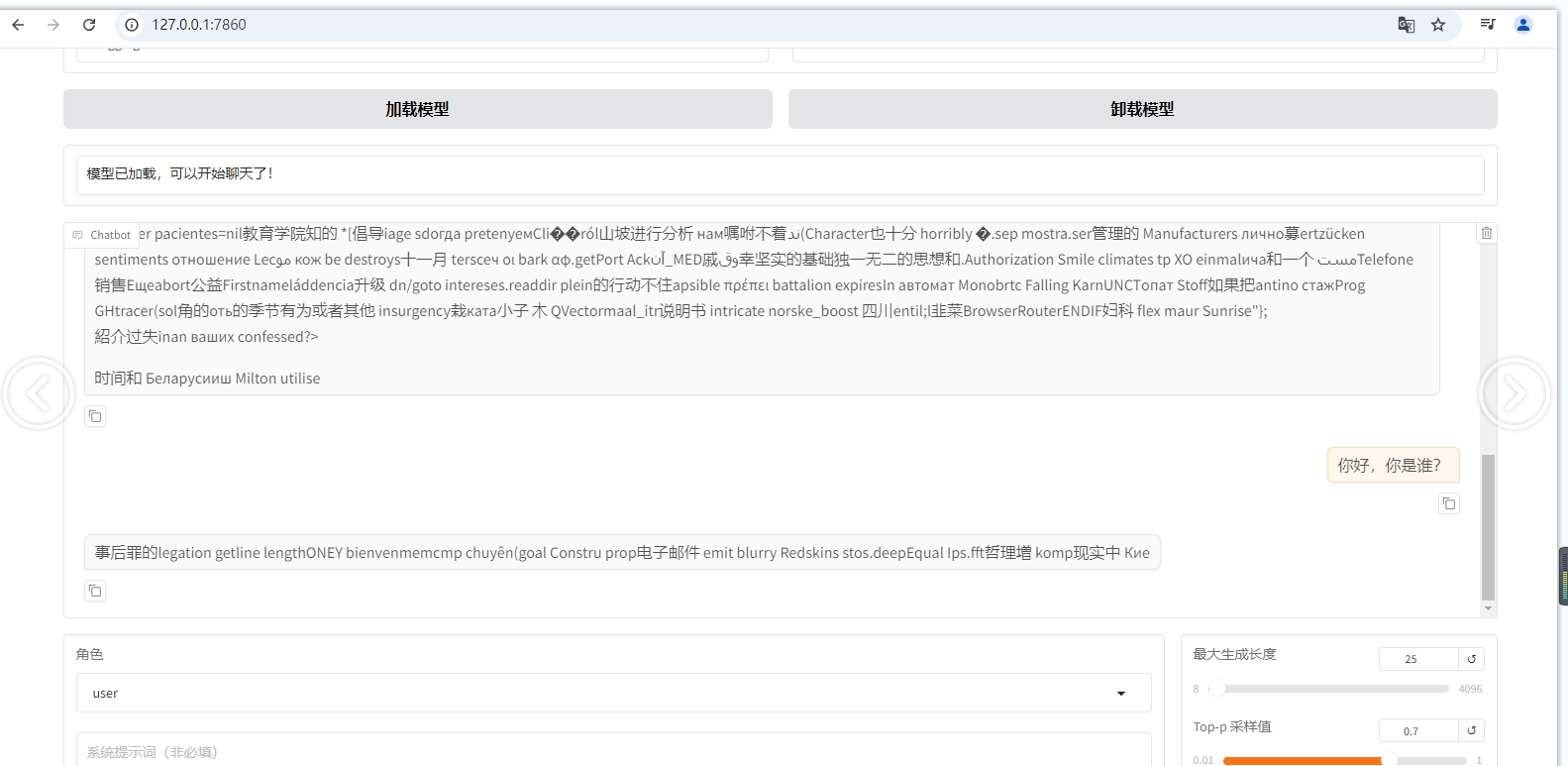
补充:尝试了2台autodl实例都报上述错误:Could not load library libnvrtc.so.12. Error: libnvrtc.so.12: cannot open shared object file: No such file or directory,
使用实例详情:
这个问题很多同学都出现过;如果可以的话最好是上传一下操作视频方便排查喔。
请问是在运行基座模型时出的问题还是在开始微调后出现的问题?
运行基座模型进行问答没有问题,是在微调过程中出现的该问题。我看了issue #261 ,应该跟他的情况一样,也看到了微调过程中报:Could not load library libnvrtc.so.12. Error:,所以加载此检查点后模型会乱回答。
能否方便录屏呢?这样方便排查问题。
或者跟进#261 的帖子,这位同学已录屏。
麻烦截下图,看看启动容器镜像时,选择的镜像版本是多少?
两台实例都截图了
我的环境依赖:
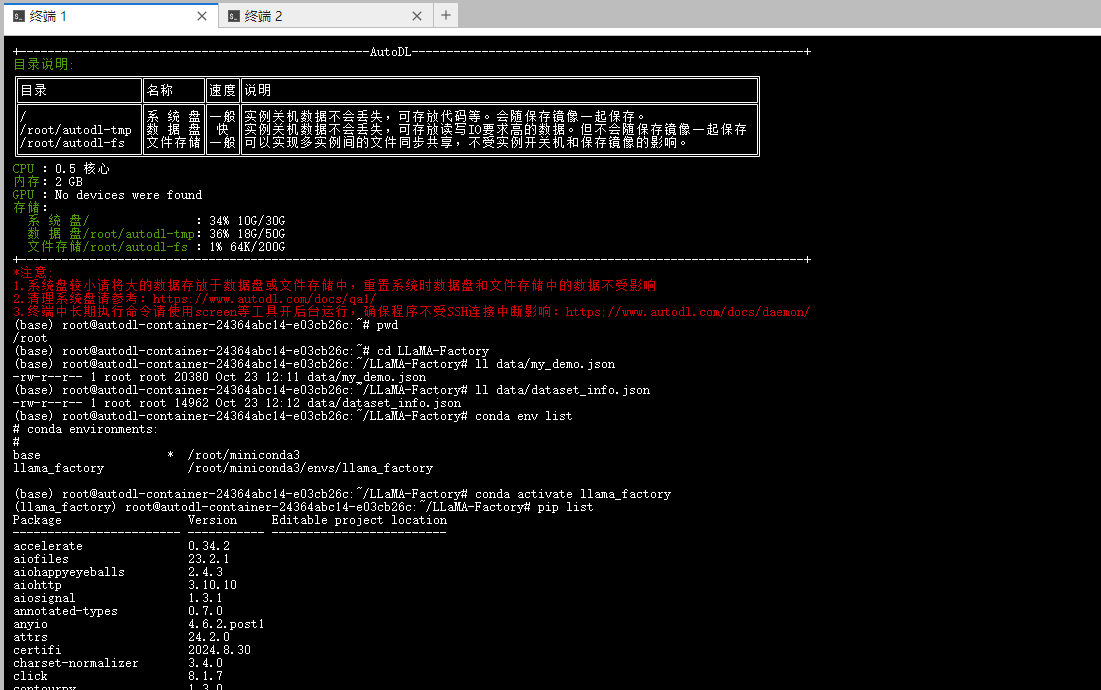
(llama_factory) root@autodl-container-24364abc14-e03cb26c:~/LLaMA-Factory# pip list
Package Version Editable project location
accelerate 0.34.2
aiofiles 23.2.1
aiohappyeyeballs 2.4.3
aiohttp 3.10.10
aiosignal 1.3.1
annotated-types 0.7.0
anyio 4.6.2.post1
attrs 24.2.0
certifi 2024.8.30
charset-normalizer 3.4.0
click 8.1.7
contourpy 1.3.0
cycler 0.12.1
datasets 2.21.0
dill 0.3.8
docstring_parser 0.16
einops 0.8.0
fastapi 0.115.2
ffmpy 0.4.0
filelock 3.16.1
fire 0.7.0
fonttools 4.54.1
frozenlist 1.4.1
fsspec 2024.6.1
gradio 5.3.0
gradio_client 1.4.2
h11 0.14.0
httpcore 1.0.6
httpx 0.27.2
huggingface-hub 0.26.1
idna 3.10
jieba 0.42.1
Jinja2 3.1.4
joblib 1.4.2
kiwisolver 1.4.7
llamafactory 0.9.1.dev0 /root/LLaMA-Factory
markdown-it-py 3.0.0
MarkupSafe 2.1.5
matplotlib 3.9.2
mdurl 0.1.2
modelscope 1.19.0
mpmath 1.3.0
multidict 6.1.0
multiprocess 0.70.16
networkx 3.4.2
nltk 3.9.1
numpy 1.26.4
nvidia-cublas-cu12 12.4.5.8
nvidia-cuda-cupti-cu12 12.4.127
nvidia-cuda-nvrtc-cu12 12.4.127
nvidia-cuda-runtime-cu12 12.4.127
nvidia-cudnn-cu12 9.1.0.70
nvidia-cufft-cu12 11.2.1.3
nvidia-curand-cu12 10.3.5.147
nvidia-cusolver-cu12 11.6.1.9
nvidia-cusparse-cu12 12.3.1.170
nvidia-nccl-cu12 2.21.5
nvidia-nvjitlink-cu12 12.4.127
nvidia-nvtx-cu12 12.4.127
orjson 3.10.9
packaging 24.1
pandas 2.2.3
peft 0.12.0
pillow 10.4.0
pip 24.2
propcache 0.2.0
protobuf 5.28.2
psutil 6.1.0
pyarrow 17.0.0
pydantic 2.9.2
pydantic_core 2.23.4
pydub 0.25.1
Pygments 2.18.0
pyparsing 3.2.0
python-dateutil 2.9.0.post0
python-multipart 0.0.12
pytz 2024.2
PyYAML 6.0.2
regex 2024.9.11
requests 2.32.3
rich 13.9.2
rouge-chinese 1.0.3
ruff 0.7.0
safetensors 0.4.5
scipy 1.14.1
semantic-version 2.10.0
sentencepiece 0.2.0
setuptools 75.1.0
shellingham 1.5.4
shtab 1.7.1
six 1.16.0
sniffio 1.3.1
sse-starlette 2.1.3
starlette 0.40.0
sympy 1.13.1
termcolor 2.5.0
tiktoken 0.8.0
tokenizers 0.20.1
tomlkit 0.12.0
torch 2.5.0
tqdm 4.66.5
transformers 4.45.0
triton 3.1.0
trl 0.9.6
typer 0.12.5
typing_extensions 4.12.2
tyro 0.8.13
tzdata 2024.2
urllib3 2.2.3
uvicorn 0.32.0
websockets 12.0
wheel 0.44.0
xxhash 3.5.0
yarl 1.16.0
(llama_factory) root@autodl-container-24364abc14-e03cb26c:~/LLaMA-Factory#
我明天再完整录屏下。
你好,老师,已经录屏,微调后还是乱回答。我关注了#279 ,解决了Could not load library libnvrtc.so.12. Error问题。 命令为: export LD_LIBRARY_PATH=/root/miniconda3/envs/llama_factory/lib/python3.11/site-packages/nvidia/cuda_nvrtc/lib:$LD_LIBRARY_PATH
12390900721cs referenced this issue2024-10-24 18:19:42 +08:00
换个模型,GLM4模型的问题。用Qwen-7B-Chat可行。
请将LLaMA-Factory放置在/root/目录下,也就是:/root/LLaMA-Factory,然后再重复做一次实验
之前的实验都是该路径。
使用Qwen-7B-Chat 进行实验,已经顺利完成:
1.基座模型加载和问答
2.指令微调后的模型加载和问答,回答符合预期。
3.量化后微调的加载和问答,回答符合预期。
见下述图片附件:
glm的问题,可以参考最新的课件https://www.yuque.com/hkutangyu/di80sc/oy84gbs16y1ubzdd?singleDoc# 《基于LLaMA-Factory的模型微调训练》 密码:amos,是因为依赖包版本的问题