【求助帖】LLM->多模态理论+案例讲解--video-llava运行报错 #585
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#585
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
启动成功,但提问环节报错
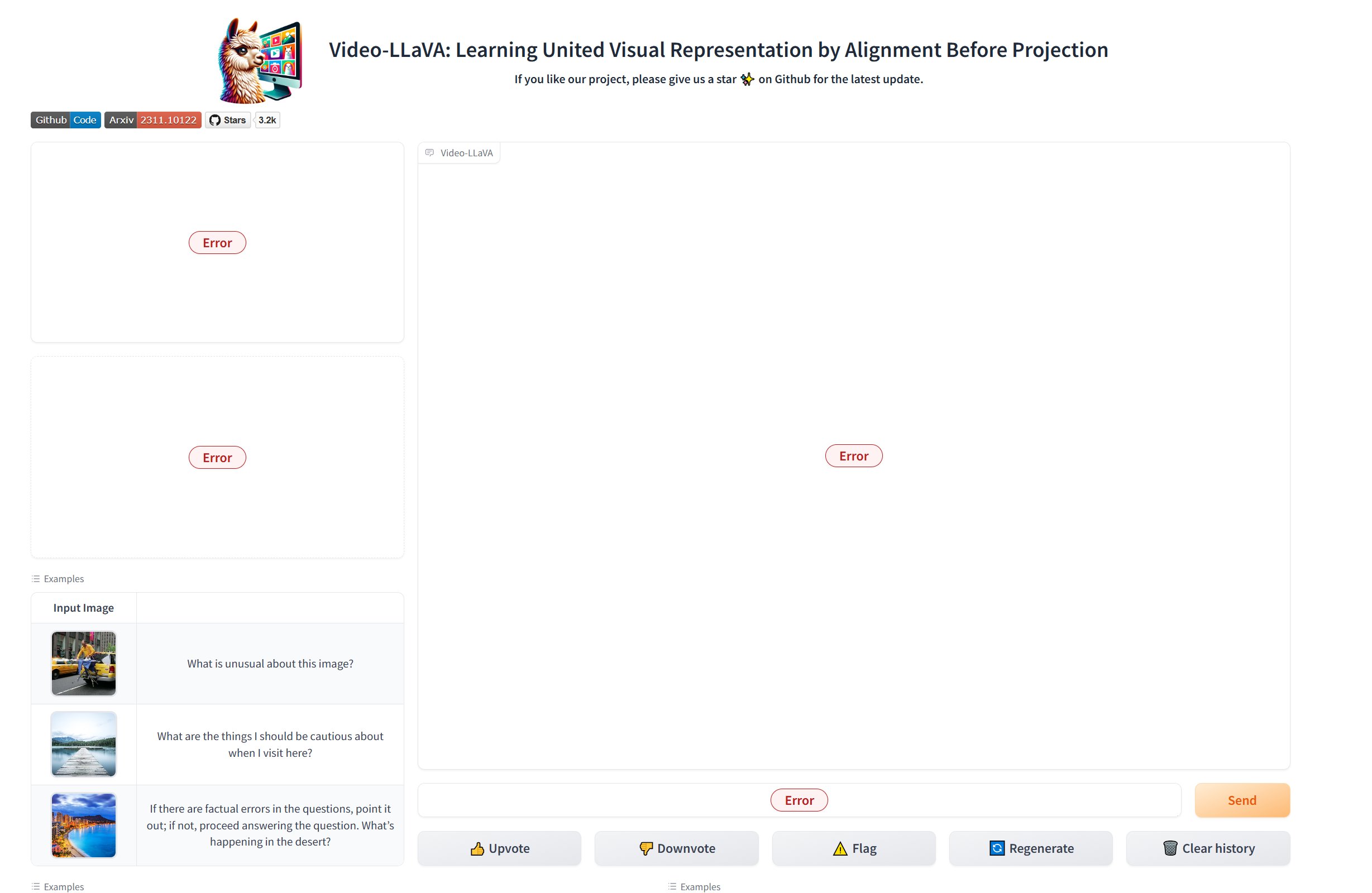
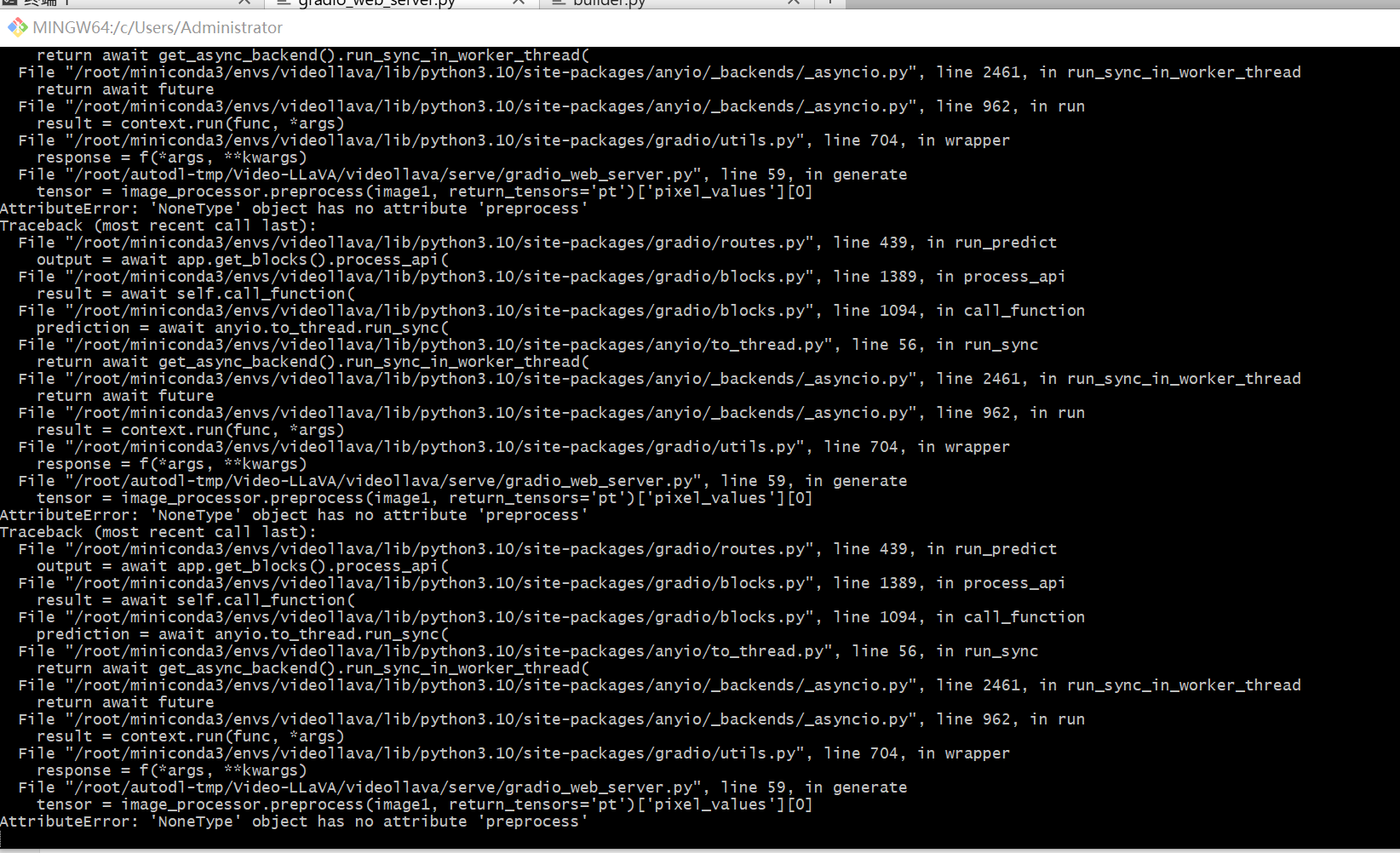

图片处理报错
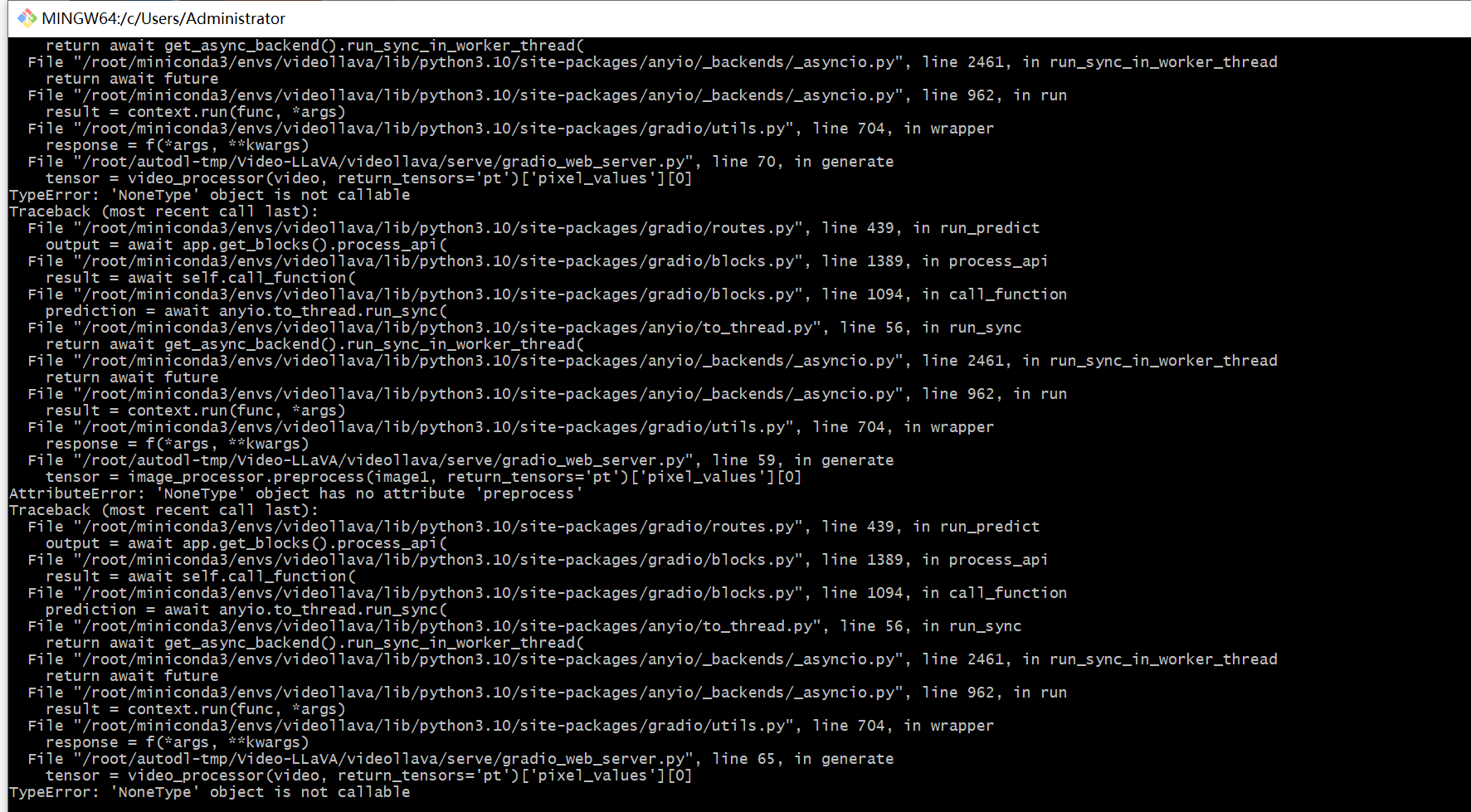
视频处理报错
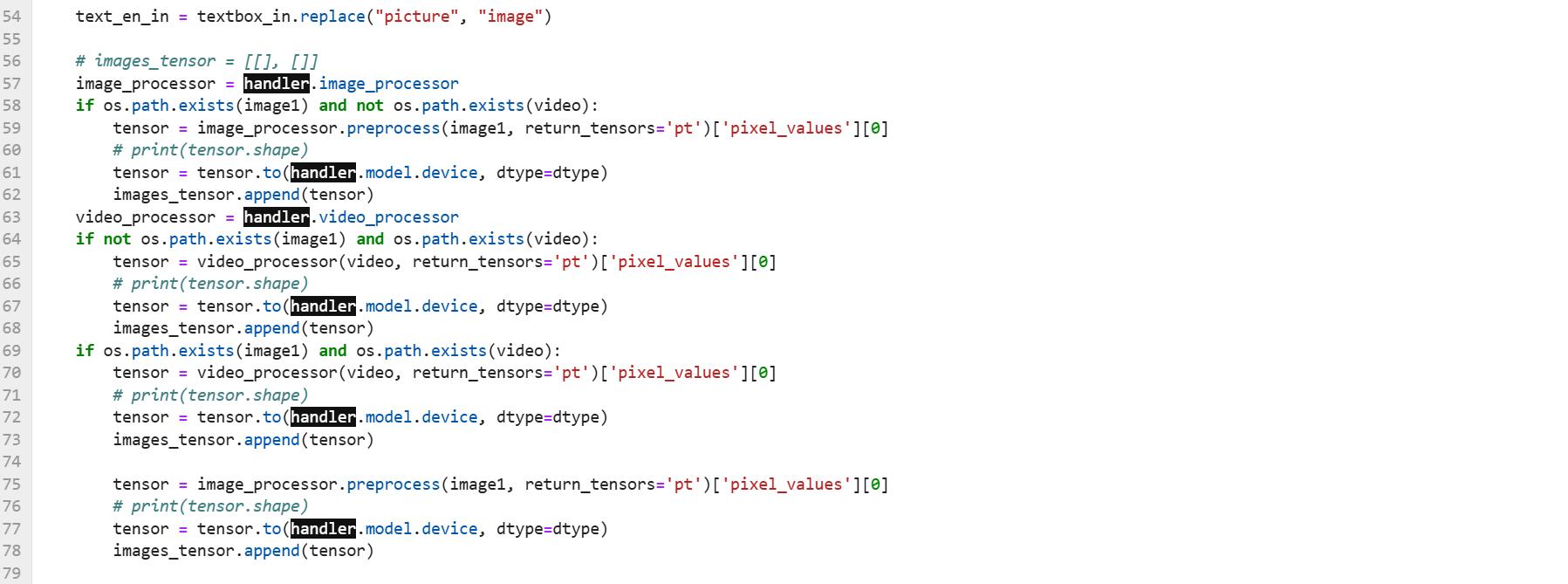
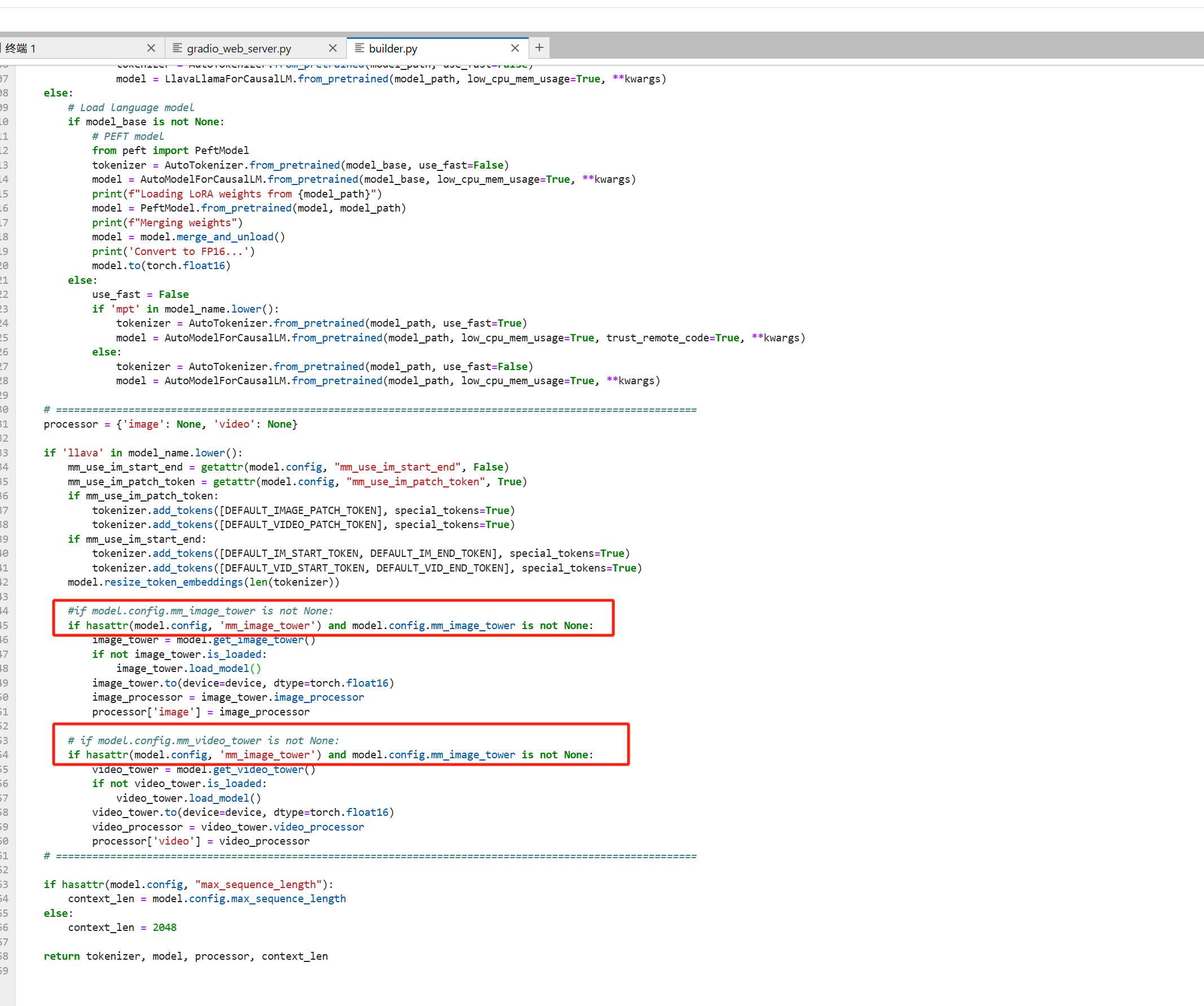
之前启动报AttributeError: 'LlamaConfig' object has no attribute 'mm_vision_tower'这个错,修改了builder.py文件,修改后课成功启动,修改如下:
我没遇到过,可以参考下:
变量 image_processor 在被使用之前没有被正确地赋值或初始化。 具体来说,在文件 /root/autodl-tmp/Video-LLAVA/videollava/serve/gradio_web_server.py 的第 59 行代码中,尝试使用 image_processor 对象的 preprocess 方法,但是此时 image_processor 是 None,导致了错误。
可能的原因: image_processor 未正确加载或初始化: 在 gradio_web_server.py 文件或者其他相关文件中,负责加载或初始化 image_processor 的代码可能出现了问题,导致它最终的值为 None。 例如,加载模型或配置文件的代码可能失败了。
video_processor也报错了,和image_processor不一样,关于启动报错的处理方法有问题吗(修改builder.py文件)
我一般会先检查torch、cuda版本,然后检查transformers的版本,之后看下代码库的issue,一般很少改builder文件。
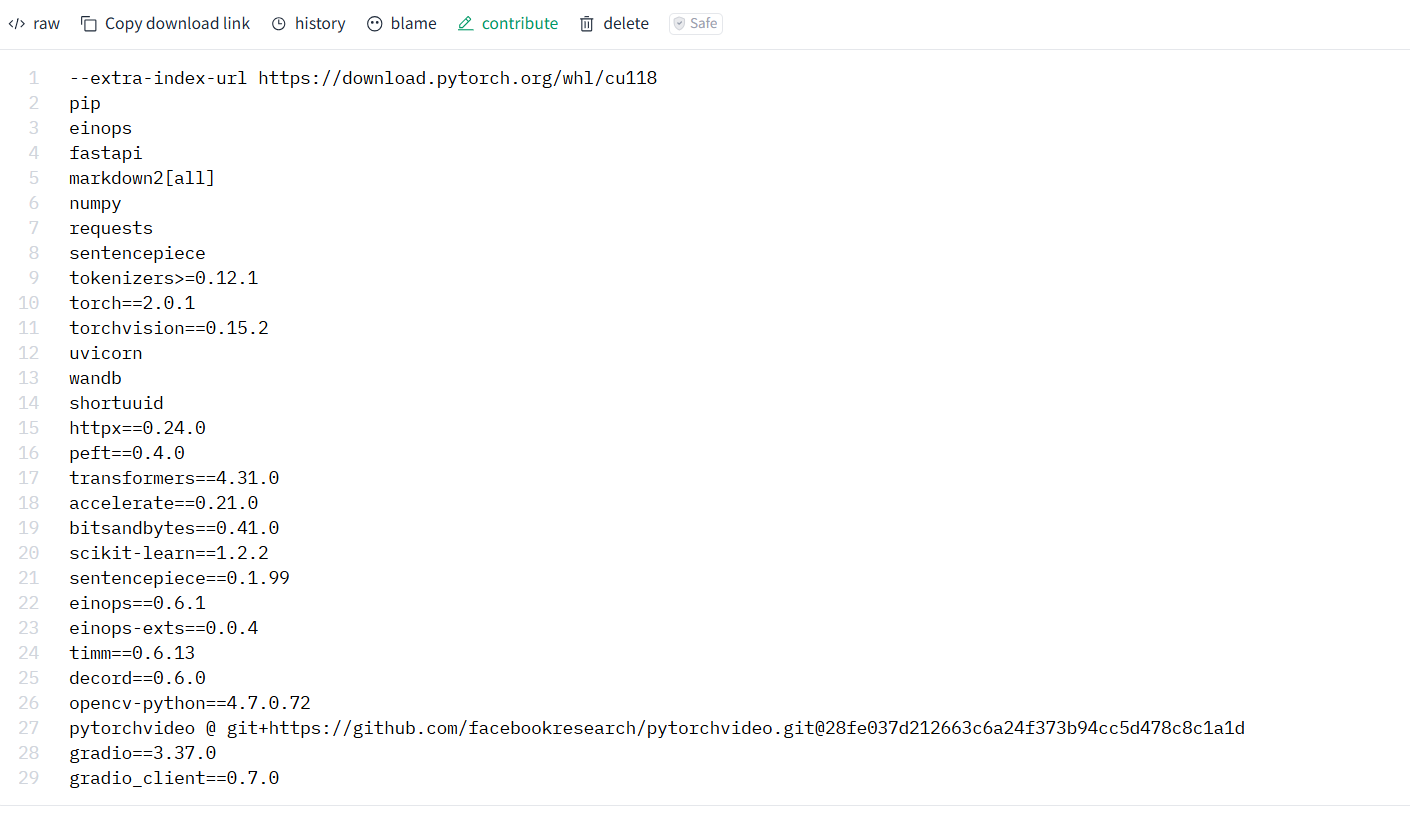
AttributeError: 'LlamaConfig' object has no attribute 'mm_vision_tower'正常这个问题如何解决呢,使用的依赖版本是这个
还有一个通用性问题,就是https://github.com/PKU-YuanGroup/Video-LLaVA.git这个网站上没指明模型文件是啥,我应该如何去找对应的模型文件下载
图一是我的实例配置
文件是我的conda环境配置