2405期 LLaMA-Factory 8 bit 量化微调 报错,尝试多个方案没有结果,使用的参考文档如附件。 #626
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#626
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
03/16/2025 07:27:24 - WARNING - llamafactory.hparams.parser - We recommend enable
upcast_layernormin quantized training.03/16/2025 07:27:24 - INFO - llamafactory.hparams.parser - Process rank: 0, device: cuda:0, n_gpu: 1, distributed training: False, compute dtype: torch.bfloat16
Downloading Model to directory: /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat
2025-03-16 07:27:25,322 - modelscope - WARNING - Using branch: master as version is unstable, use with caution
[INFO|configuration_utils.py:670] 2025-03-16 07:27:25,706 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:670] 2025-03-16 07:27:25,709 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:739] 2025-03-16 07:27:25,710 >> Model config ChatGLMConfig {
"_name_or_path": "/root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": [
151329,
151336,
151338
],
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1.5625e-07,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_hidden_layers": 40,
"num_layers": 40,
"original_rope": true,
"pad_token_id": 151329,
"padded_vocab_size": 151552,
"post_layer_norm": true,
"rmsnorm": true,
"rope_ratio": 500,
"seq_length": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.45.0",
"use_cache": true,
"vocab_size": 151552
}
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:25,717 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:25,717 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:25,717 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:25,717 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:25,717 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2478] 2025-03-16 07:27:26,154 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[INFO|configuration_utils.py:670] 2025-03-16 07:27:26,155 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:670] 2025-03-16 07:27:26,156 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:739] 2025-03-16 07:27:26,157 >> Model config ChatGLMConfig {
"_name_or_path": "/root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": [
151329,
151336,
151338
],
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1.5625e-07,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_hidden_layers": 40,
"num_layers": 40,
"original_rope": true,
"pad_token_id": 151329,
"padded_vocab_size": 151552,
"post_layer_norm": true,
"rmsnorm": true,
"rope_ratio": 500,
"seq_length": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.45.0",
"use_cache": true,
"vocab_size": 151552
}
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:26,158 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:26,158 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:26,158 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:26,158 >> loading file tokenizer_config.json
[INFO|tokenization_utils_base.py:2212] 2025-03-16 07:27:26,158 >> loading file tokenizer.json
[INFO|tokenization_utils_base.py:2478] 2025-03-16 07:27:26,519 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
03/16/2025 07:27:26 - INFO - llamafactory.data.template - Add <|user|>,<|observation|> to stop words.
03/16/2025 07:27:26 - INFO - llamafactory.data.loader - Loading dataset my_demo.json...
training example:
input_ids:
[151331, 151333, 151336, 198, 109377, 151337, 198, 121658, 3837, 101328, 118327, 15457, 113255, 3837, 98444, 98582, 118327, 15457, 100917, 99134, 110230, 15457, 113255, 3837, 118295, 100119, 99526, 1773, 98964, 106546, 98342, 107410, 98540, 110000, 11314, 151329]
inputs:
[gMASK] <|user|>
你好 <|assistant|>
您好,我是数据中心AI助手,一个由数据中心AI研发中心开发的AI助手,很高兴认识您。请问我能为您做些什么? <|endoftext|>
label_ids:
[151329, -100, -100, -100, -100, -100, 198, 121658, 3837, 101328, 118327, 15457, 113255, 3837, 98444, 98582, 118327, 15457, 100917, 99134, 110230, 15457, 113255, 3837, 118295, 100119, 99526, 1773, 98964, 106546, 98342, 107410, 98540, 110000, 11314, 151329]
labels:
<|endoftext|>
您好,我是数据中心AI助手,一个由数据中心AI研发中心开发的AI助手,很高兴认识您。请问我能为您做些什么? <|endoftext|>
[INFO|configuration_utils.py:670] 2025-03-16 07:27:28,825 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:670] 2025-03-16 07:27:28,826 >> loading configuration file /root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat/config.json
[INFO|configuration_utils.py:739] 2025-03-16 07:27:28,827 >> Model config ChatGLMConfig {
"_name_or_path": "/root/autodl-tmp/modelscope/models/ZhipuAI/glm-4-9b-chat",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": [
151329,
151336,
151338
],
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1.5625e-07,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_hidden_layers": 40,
"num_layers": 40,
"original_rope": true,
"pad_token_id": 151329,
"padded_vocab_size": 151552,
"post_layer_norm": true,
"rmsnorm": true,
"rope_ratio": 500,
"seq_length": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.45.0",
"use_cache": true,
"vocab_size": 151552
}
03/16/2025 07:27:28 - INFO - llamafactory.model.model_utils.quantization - Quantizing model to 8 bit with bitsandbytes.
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
Traceback (most recent call last):
File "/root/miniconda3/envs/llama_factory/bin/llamafactory-cli", line 8, in
sys.exit(main())
^^^^^^
File "/root/LLaMA-Factory/src/llamafactory/cli.py", line 111, in main
run_exp()
File "/root/LLaMA-Factory/src/llamafactory/train/tuner.py", line 50, in run_exp
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
File "/root/LLaMA-Factory/src/llamafactory/train/sft/workflow.py", line 48, in run_sft
model = load_model(tokenizer, model_args, finetuning_args, training_args.do_train)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/LLaMA-Factory/src/llamafactory/model/loader.py", line 162, in load_model
model = load_class.from_pretrained(**init_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/llama_factory/lib/python3.11/site-packages/transformers/models/auto/auto_factory.py", line 559, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/root/miniconda3/envs/llama_factory/lib/python3.11/site-packages/transformers/modeling_utils.py", line 3446, in from_pretrained
hf_quantizer.validate_environment(
File "/root/miniconda3/envs/llama_factory/lib/python3.11/site-packages/transformers/quantizers/quantizer_bnb_8bit.py", line 111, in validate_environment
raise ValueError(
ValueError: You have a version of
bitsandbytesthat is not compatible with 8bit inference and training make sure you have the latest version ofbitsandbytesinstalled是否严格按照教案里面的pip requirements.txt安装包,因为换了版本可能存在不兼容。
是否安装了特定依赖?如下图所示:
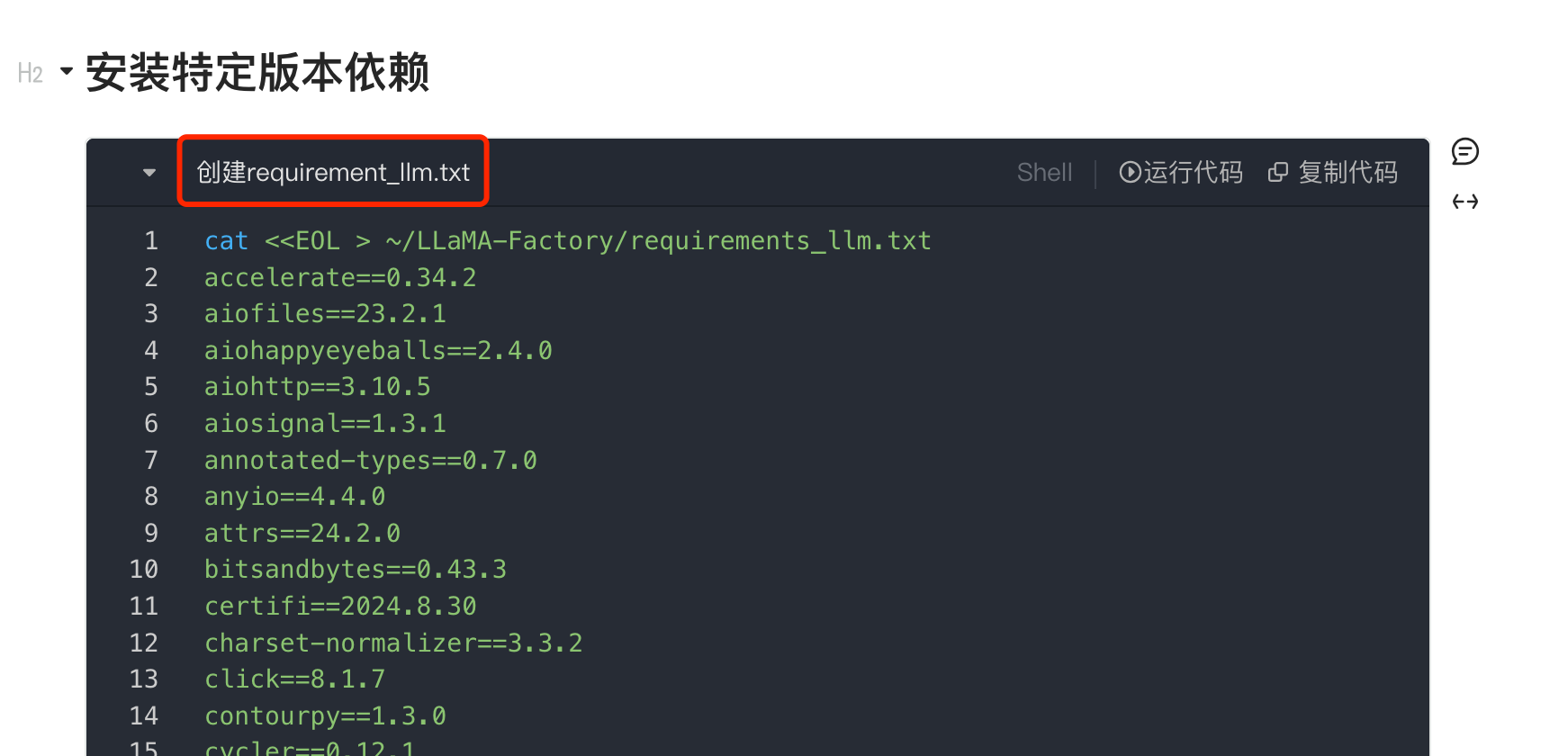
使用pip install -r requirements_llm.txt命令安装,具体教程可参考:
https://www.yuque.com/hkutangyu/di80sc/oy84gbs16y1ubzdd?singleDoc# 《基于LLaMA-Factory的模型微调训练》 密码:amos
这个依赖项是从哪里获取的,麻烦解释一下,以便后续自己遇到问题可以自行先解决
该依赖项是老师经过测试可行的版本。