【求助帖】32-25.3.25-实时网页信息爬取+RAG的舆情分析系统-林辉老师 #691
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#691
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
由于上节课已经创建了一个mysql的数据库,我想不重复创建mysql,就把这次的表格创建在之前的数据库中。但是pyway migrate就报错了想了解为什么。报错原因:raise RuntimeError(DIFF_CHECKSUM_ERROR % (local_migration.name,
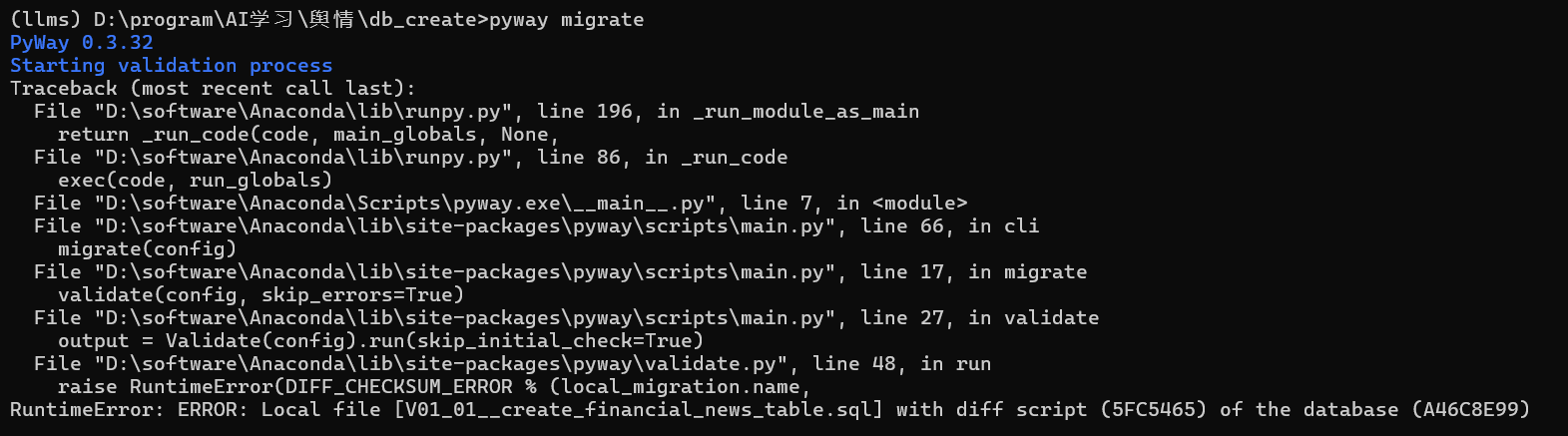
RuntimeError: ERROR: Local file [V01_01__create_financial_news_table.sql] with diff script (5FC5465) of the database (A46C8E99)
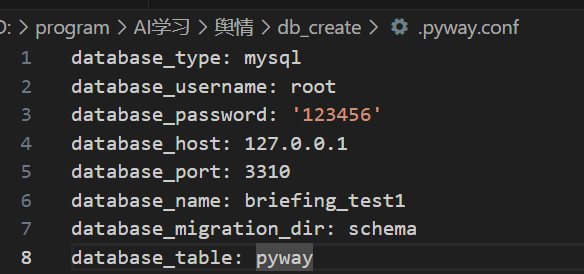
本节课中,db_create中的.pyway.conf我已经做了相应的修改
我在拉取xinference的时候报错是为什么docker: error pulling image configuration: download failed after attempts=1: toomanyrequests: too many requests.
See 'docker run --help'.
代码是
docker run -d -e XINFERENCE_MODEL_SRC=modelscope -v D:\program\AItools\xinference:/root/.xinference -v D:\program\AItools\xinference/.cache/huggingface:/root/.cache/huggingface -v D:\program\AItools\xinference/.cache/modelscope:/root/.cache/modelscope -p 9997:9997 registry.cn-hangzhou.aliyuncs.com/xprobe_xinference/xinference:latest
根据这个代码我拉取下了这个镜像。然后我再次执行时,出现容器的ID:c8eeb7225013682b1968ff5c8edc9a4804252064aaf9929f082c767289d737f0。但是我在dock desktop上看到这个容器的status是exited状态,并且怎么试都不能启动,这是为什么
是否是因为电脑内存不够,所以docker的镜像就打不开
在具体执行的时候遇到另一个问题,main.py执行,日志显示一下内容,说明知识库链接是正常的,但是我的fastgpt里面的知识库没有内容,依旧为空。这是为什么。
你的电脑有GPU吗,如果没有GPU就使用CPU版本,在拉取容器的时候需要在镜像名称后面加CPU,然后最好就是使用linux系统来部署xinference,
这个是你没有正确部署embedding模型,无法使用embedding模型进行向量化,然后知识库就会为空,你可以检查下embedding模型
dataset_name_2_dataset_id {'携程旅游': '6807ad759233f22a626288a6', '2': '680795eb60cdb83a5a1fd47f', '1': '680795dc60cdb83a5a1fd285', '舆情知识库': '6807917660cdb83a5a1fd0b7', '财经新闻': '67ed5fab3be638e5bd0aa0a7'}我获取了知识库的列表,是有1和2的知识库的但是不知道为什么页面上没有展示出来
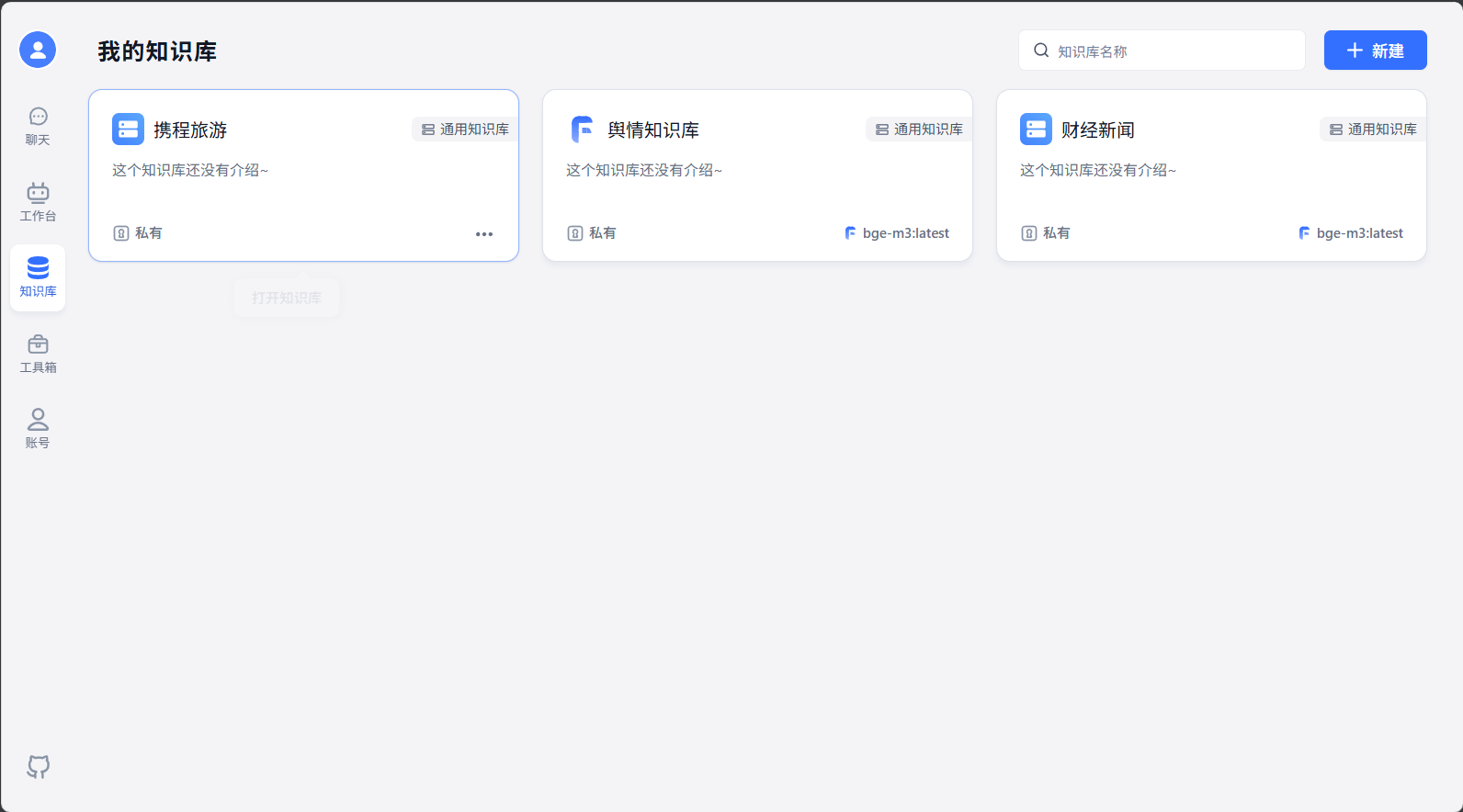
能否解释一下为什么会有crawl和interface两个文件,因为我看crawl已经实现了爬取,创建数据库,创建知识库的闭环,那interface的作用是什么。
在工作流中需要调用接口去查询数据库中的数据,这个interface就是提供这个接口可以让工作流去调用查询数据库中的数据
crawl是从网上爬数据下来保存到数据库中
def query_dataset(): """ 查询知识库 :return: """ dataset_dict = {} query_dataset_url = rf'{OPENAI_API_BASE_URL}/core/dataset/list' headers = {"Content-Type": "application/json", "Authorization": f"Bearer {OPENAI_API_KEY}"} result = requests.post(url=query_dataset_url, headers=headers) try: ret = result.json() print(ret)我用这个function去查找我的知识库,里面包含{'舆情知识库': '6807917660cdb83a5a1fd0b7', '携程旅游': '6807ad759233f22a626288a6', '2': '680795eb60cdb83a5a1fd47f', '1': '680795dc60cdb83a5a1fd285', '财经新闻': '67ed5fab3be638e5bd0aa0a7'}但是实际我的页面上没有1和2这两个知识库,这是为什么。重启fastgpt容器也不行,方便的话安排远程
知识库1和2是不是在这个目录里面呢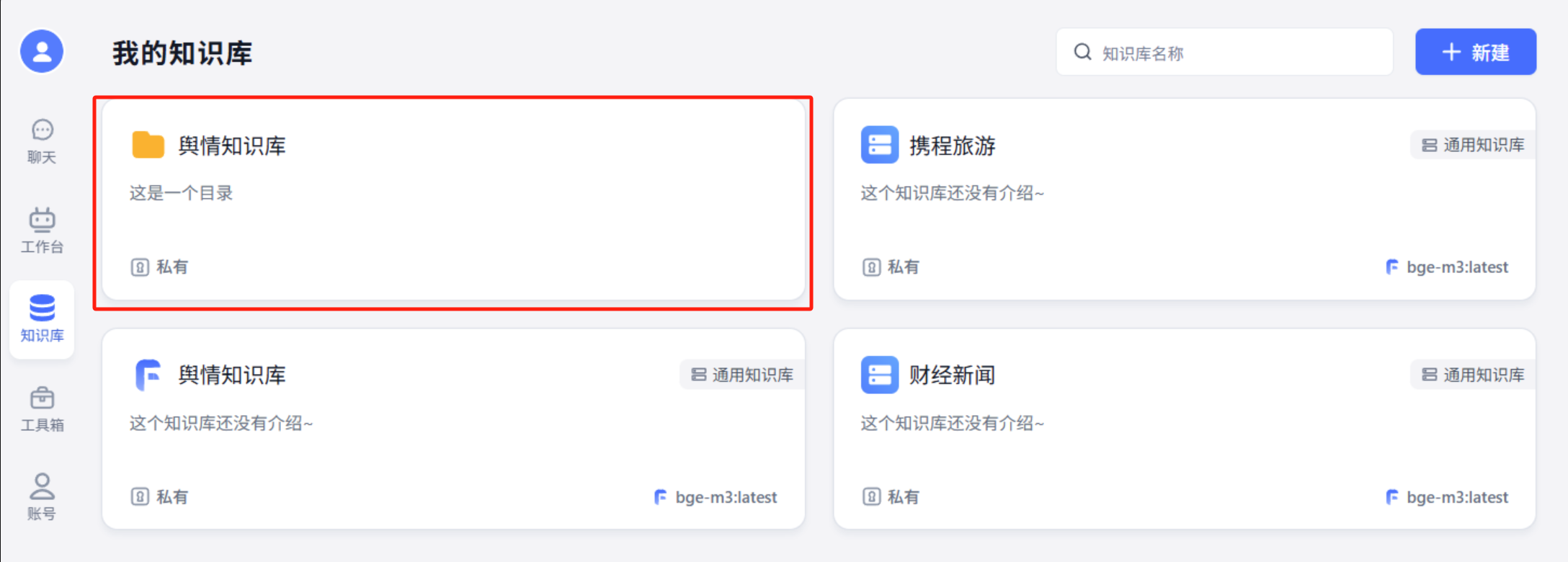
不在这里面,这个文件夹里面是空的