本地开源模型部署代码理解 #72
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
1 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#72
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
python -m fastchat.serve.controller --host 0.0.0.0这个命令启动了 FastChat 的控制器。控制器负责协调和管理整个系统的运行,包括接收用户请求、分配任务给模型工作节点等。
python -m fastchat.serve.model_worker --model-path /dataset/CodeLlama-7b-hf/ --host 0.0.0.0 --num-gpus 4 --max-gpu-memory 15GiB这个命令启动了 FastChat 的模型工作节点。模型工作节点加载指定路径下的模型,通过指定数量的 GPU 进行模型推理或生成,并限制每个 GPU 的最大内存使用量。
python -m fastchat.serve.openai_api_server --host 0.0.0.0这个命令启动了 FastChat 的 OpenAI API 服务器。这个服务器用于接收来自控制器的请求,并调用 OpenAI API 来生成对话或响应用户的查询。
FastChat 是一个开源项目,用于构建基于预训练语言模型的对话系统。它通常使用了像 OpenAI 的 GPT 系列模型或类似的模型来实现自然语言理解和生成任务。FastChat 的设计旨在支持高并发、实时的对话交互,利用 GPU 加速进行模型推理。
主要特点和功能包括:
整体工作流程:整体工作流程涉及到启动 FastChat 的各个组件,并使它们协同工作以提供对话服务。这些命令组合在一起构成了一个分布式的对话系统架构,能够处理并发的用户请求,使用 GPU 加速模型推理,并利用 OpenAI 的强大模型生成能力来实现复杂的对话交互。
控制器扮演中心协调角色,它的作用是接收用户的请求,并根据系统的负载情况和请求特性决定将请求发送给哪个模型工作节点处理。控制器一般会监听特定的端口,等待来自客户端的连接和请求。
每个模型工作节点加载预训练的对话模型,并利用 GPU 进行推理和生成响应。这些节点的数量和配置通常取决于系统的需求和性能要求。
工作流程:
python -m fastchat.serve.model_worker --model-path /dataset/CodeLlama-7b-hf/ --host 0.0.0.0 --num-gpus 4 --max-gpu-memory 15GiB工作流程:
这种整体工作流程适用于构建高性能的对话系统,特别是需要处理大规模并发请求和利用 GPU 加速的自然语言处理应用场景。
运行结果:
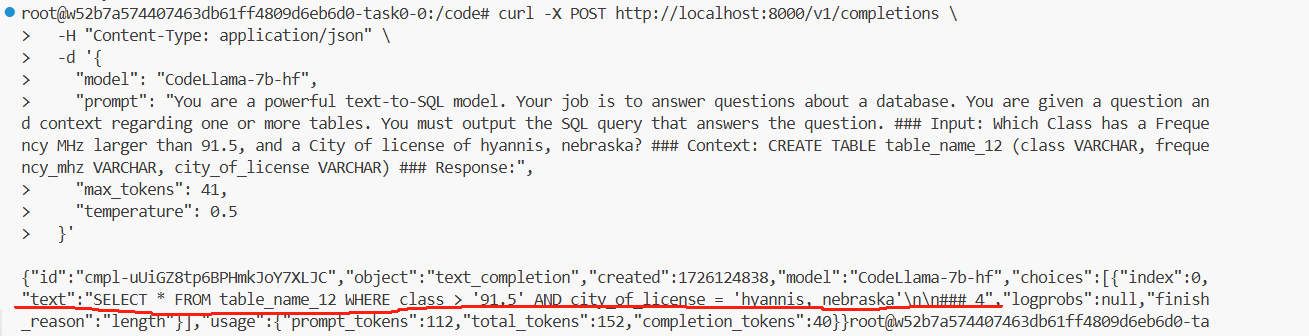
可以看出这里codellama得到的结果并不好,需要在后续进行微调。