llamafactory-模型量化作业20241022 #28
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
本次实验采用OFTQ进行量化.关于OFTQ的解释如下:
OFTQ(On-the-fly Quantization)指的是模型无需校准数据集,直接在推理阶段进行量化。OFTQ是一种动态的后训练量化技术. OFTQ在保持性能的同时。 因此,在使用OFTQ量化方法时,您需要指定预训练模型、指定量化方法 quantization_method 和指定量化位数 quantization_bit
关于为何选择bitsandbytes量化
有一段关于它的说明是区别于 GPTQ, bitsandbytes 是一种动态的后训练量化技术。bitsandbytes 使得大于 1B 的语言模型也能在 8-bit 量化后不过多地损失性能。 经过bitsandbytes 8-bit 量化的模型能够在保持性能的情况下节省约50%的显存。
注意:不管这个量化的参数配置、量化位数等如何选择.机制本身就基本会让其模型会有性能损失.
前置环境要求
模型选择: GLM4-9B-Chat
显卡显存建议: 20GB以上
需要安装llamafactory
实验1-量化位数4
启动量化位数4的启动命令 关键参数是quantization_method指定量化方法为bitsandbytes.位数是4
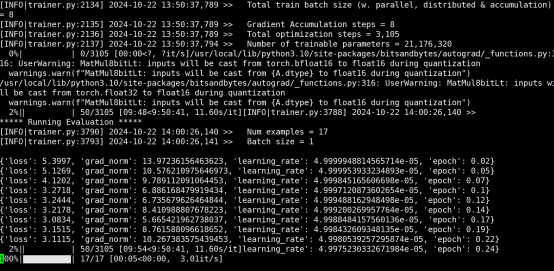
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --model_name_or_path /fine_tuning/model_path \ --finetuning_type lora \ --do_train true \ --stage sft \ --quantization_bit 4 \ --quantization_method bitsandbytes \ --dataset_dir /fine_tuning/dataset \ --dataset trainFile \ --template glm4 \ --cutoff_len 1024 \ --overwrite_cache true \ --preprocessing_num_workers 16 \ --output_dir /fine_tuning/work_dir/lora-sft-${currentTime}-adapter \ --overwrite_output_dir true \ --plot_loss true \ --save_steps 500 \ --save_total_limit 5 \ --logging_steps 5 \ --learning_rate 5e-05 \ --num_train_epochs 15 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --warmup_steps 0 \ --bf16 false \ --fp16 true \ --ddp_timeout 18000000000000 \ --val_size 0.01 \ --eval_strategy steps \ --eval_steps 50 \ --per_device_eval_batch_size 1 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_rank 8 \ --lora_target all量化4开启的日志
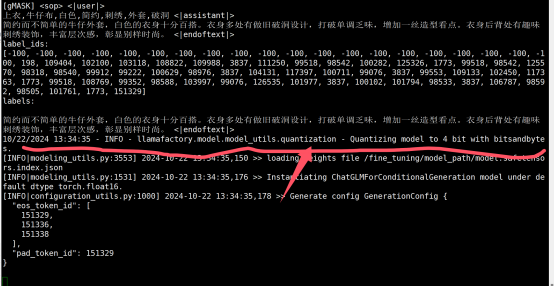
训练样本1000多个
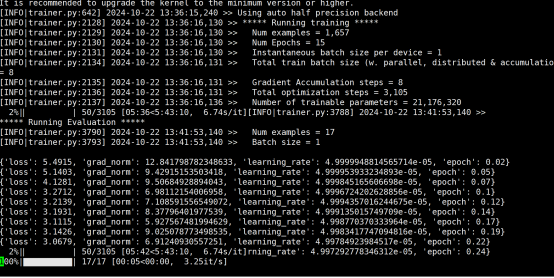
显存占用
实验2-量化位数8
启动量化位数8的启动命令 关键参数是quantization_method指定量化方法为bitsandbytes.位数是8
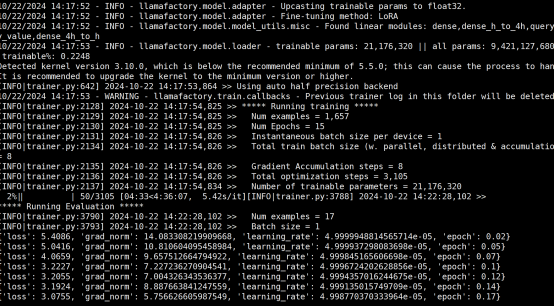
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --model_name_or_path /fine_tuning/model_path \ --finetuning_type lora \ --do_train true \ --stage sft \ --quantization_bit 8 \ --quantization_method bitsandbytes \ --dataset_dir /fine_tuning/dataset \ --dataset trainFile \ --template glm4 \ --cutoff_len 1024 \ --overwrite_cache true \ --preprocessing_num_workers 16 \ --output_dir /fine_tuning/work_dir/lora-sft-${currentTime}-adapter \ --overwrite_output_dir true \ --plot_loss true \ --save_steps 500 \ --save_total_limit 5 \ --logging_steps 5 \ --learning_rate 5e-05 \ --num_train_epochs 15 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --warmup_steps 0 \ --bf16 false \ --fp16 true \ --ddp_timeout 18000000000000 \ --val_size 0.01 \ --eval_strategy steps \ --eval_steps 50 \ --per_device_eval_batch_size 1 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_rank 8 \ --lora_target all量化8开启的日志
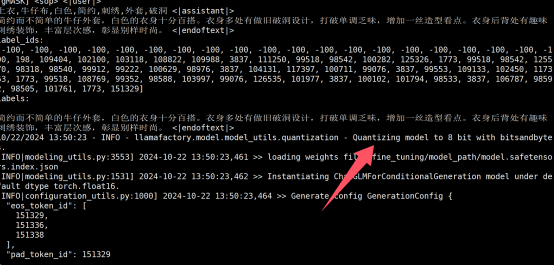
训练样本不变
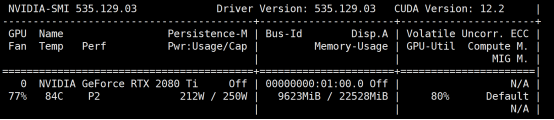
显卡占用
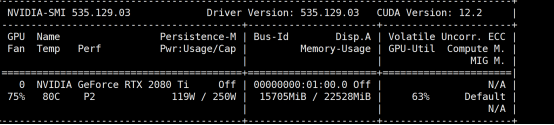
可以看到 随着量化位数的提高.显存占用会提升.同时按照一般情况来说.量化程度更低会导致模型性能更差.需要进行取舍
实验3-运行原版本-无量化bf16 位数float32
启动日志
显存占用
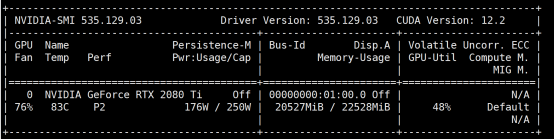
可以看到 在全精度的情况下,glm4-9b-chat完整运行需要20GB的显存
llmafactory-模型量化作业20241022to llamafactory-模型量化作业20241022