[作业]单机单卡、单机多卡、多机多卡的实验复现 #301
Labels
No Label
bug
duplicate
enhancement
help wanted
invalid
question
wontfix
No Milestone
No project
No Assignees
2 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: HswOAuth/llm_course#301
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
复现了练习册的三种试验。
提问:模型微调的任务数和多机多卡的关系是什么呢?练习里面我们开了2个任务,然后把word_size设定成了3,按照练习的例子,“总的分布式word_size即为NNODES*NPROC_PER_NODE”,如果是3机4GPU,word_size不是应该是16么?
是的,脚本里的变量名表达意思有误,已经在在线的操作文档中更新,将world_size 改为NODE_NUM。
谢谢,目前语雀的多机多卡的训练代码好像还是这样的,所以选多少张卡(多少GPU)是NPROC_PER_NODE参数,多少台机器是是NNODES。 那这个NODE_NUM是和多少个任务关联的么?和我们这个多机多卡的选择的联系是什么?谢谢
/code/multi_node_multi_gpu.sh
#!/bin/bash
export LD_LIBRARY_PATH=/opt/dtk/hip/lib:/opt/dtk/llvm/lib:/opt/dtk/lib:/opt/dtk/lib64:/opt/hyhal/lib:/opt/hyhal/lib64:/opt/dtk/.hyhal/lib:/opt/dtk/.hyhal/lib64:/opt/dtk-24.04/hip/lib:/opt/dtk-24.04/llvm/lib:/opt/dtk-24.04/lib:/opt/dtk-24.04/lib64:/opt/hyhal/lib:/opt/hyhal/lib64:/opt/dtk-24.04/.hyhal/lib:/opt/dtk-24.04/.hyhal/lib64:/usr/local/lib/:/usr/local/lib64/:/opt/mpi/lib:/opt/hwloc/lib:/opt/dtk/hip/lib:/opt/dtk/llvm/lib:/opt/dtk/lib:/opt/dtk/lib64:/opt/hyhal/lib:/opt/hyhal/lib64:/opt/mpi/lib:/opt/hwloc/lib:/usr/local/lib/:/usr/local/lib64/:$LD_LIBRARY_PATH
设置环境变量
export NCCL_DEBUG=INFO
export NCCL_IB_DISABLE=0
export NCCL_IB_HCA=mlx5
export NCCL_SOCKET_IFNAME=eth0
export GLOO_SOCKET_IFNAME=eth0
export HF_HOME=/userhome/huggingface-cache/
export HF_ENDPOINT=https://hf-mirror.com
export http_proxy=http://10.10.9.50:3000
export https_proxy=http://10.10.9.50:3000
export no_proxy=localhost,127.0.0.1
设置训练参数
export TRAIN_CONFIG=${1:-"llama2_7b_chat_lora_lawyer_e3_copy.py"}
export WORLD_SIZE=${2:-1}
export GPU=
rocm-smi| grep "auto" | wc -lexport MASTER_ADDR=${TASKSET_NAME}-task0-0.${TASKSET_NAME}
export MASTER_PORT=12222
export RANK=
echo ${HOSTNAME} | awk -F '-' '{print $NF}'export WROK_DIR="/userhome/xtuner-workdir3"
echo "GPU: ${GPU}"
echo "WORLD_SIZE: ${WORLD_SIZE}"
echo "MASTER_PORT: ${MASTER_PORT}"
echo "RANK: ${RANK}"
echo "TRAIN_CONFIG: ${TRAIN_CONFIG}"
echo "当前目录: $(pwd)"
训练模型
echo ${MASTER_ADDR}
run="NPROC_PER_NODE=${GPU} NNODES=${WORLD_SIZE} PORT=${MASTER_PORT} ADDR=${MASTER_ADDR} NODE_RANK=${RANK} xtuner train /code/${TRAIN_CONFIG} --work-dir ${WROK_DIR} --deepspeed deepspeed_zero3_offload"
打印命令
echo "$run"
执行命令
NPROC_PER_NODE=${GPU} NNODES=${WORLD_SIZE} PORT=${MASTER_PORT} ADDR=${MASTER_ADDR} NODE_RANK=${RANK} xtuner train /code/${TRAIN_CONFIG} --work-dir ${WROK_DIR} --deepspeed deepspeed_zero3_offload
NODE_NUM赋值给NNODES就是NNODES的含义,之前WORLD_SIZE赋值给NNODES就是NNODES的含义(文档已改),在【模型调试】中,一个task可以理解成启用了一台机器,在【训练管理】处,几个副本代表几台机器,下图为操作文档中的说明
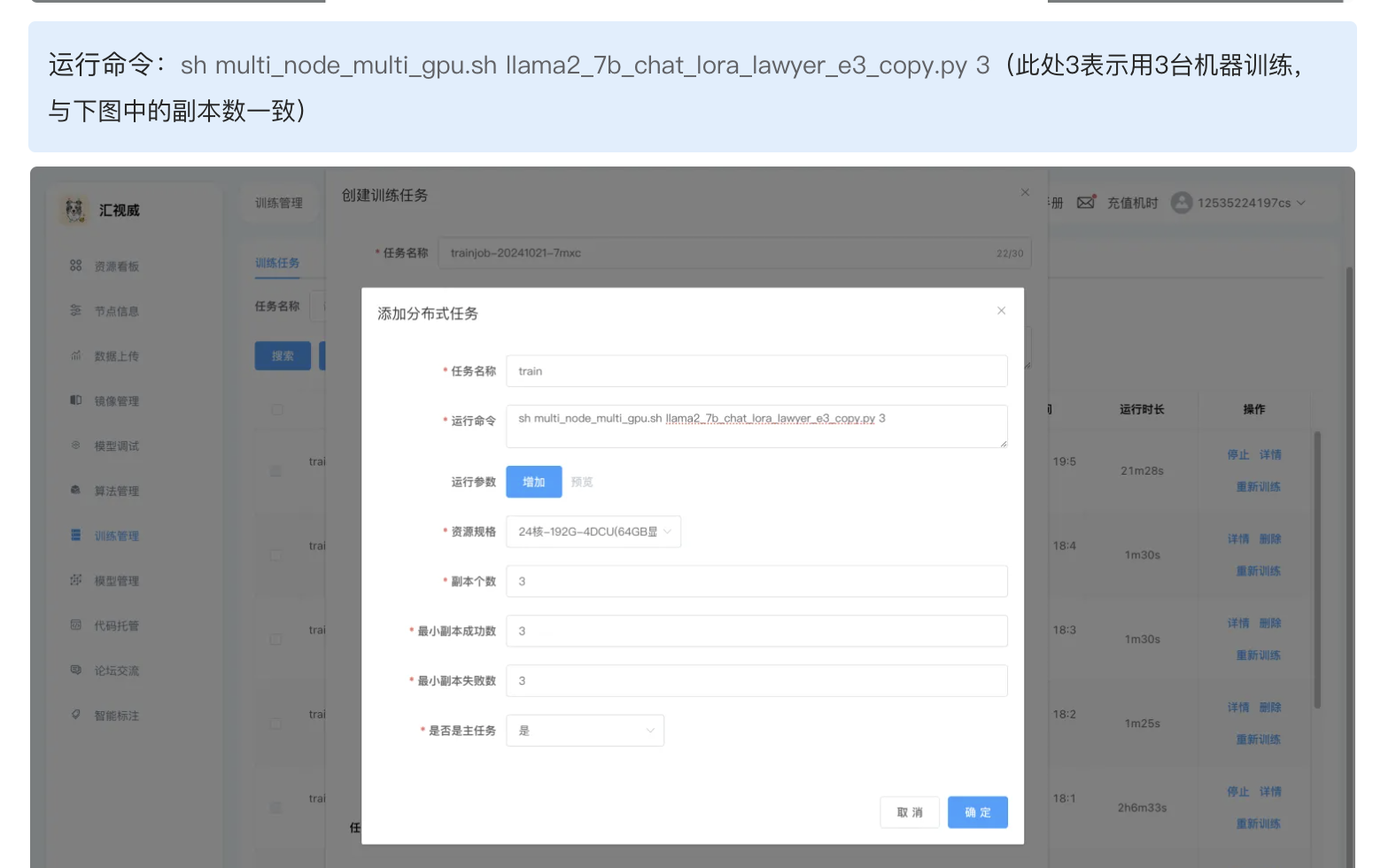
谢谢老师,收到